AI For Matching Images With Spoken Word Gets A Boost From MIT
Children learn to speak, as well as recognize objects, people, and places, long before they learn to read or write. They can learn from hearing, seeing, and interacting without being given any instructions. So why shouldn’t artificial intelligence systems be able to work the same way?
That’s the key insight driving a research project under way at MIT that takes a novel approach to speech and image recognition: Teaching a computer to successfully associate specific elements of images with corresponding sound files in order to identify imagery (say, a lighthouse in a photographic landscape) when someone in an audio clip says the word “lighthouse.”
Though in the very early stages of what could be a years-long process of research and development, the implications of the MIT project, led by PhD student David Harwath and senior research scientist Jim Glass, are substantial. Along with being able to automatically surface images based on corresponding audio clips and vice versa, the research opens a path to creating language-to-language translation without needing to go through the laborious steps of training AI systems on the correlation between two languages’ words.
That could be particularly important for deciphering languages that are dying because there aren’t enough native speakers to warrant the expensive investment in manual annotation of vocabulary by bilingual speakers, which has traditionally been the cornerstone of AI-based translation. Of 7,000 spoken languages, Harwath says, speech recognition systems have been applied to less than 100.
It could even eventually be possible, Harwath suggested, for the system to translate languages with little to no written record, a breakthrough that would be a huge boon to anthropologists.
“Because our model is just working on the level of audio and images,” Harwath told Fast Company, “we believe it to be language-agnostic. It shouldn’t care what language it’s working on.”
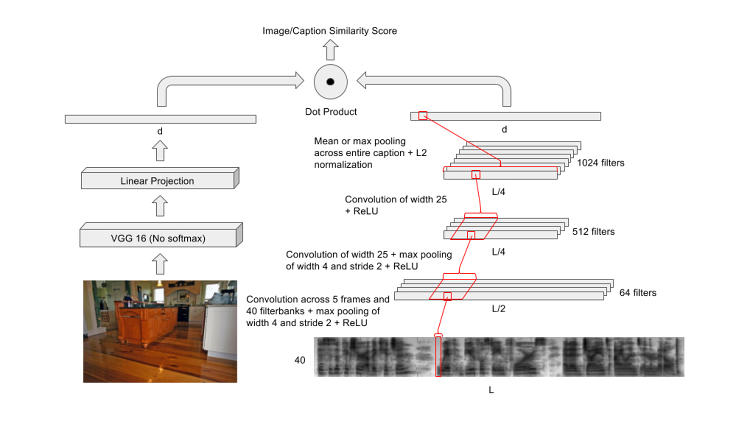
Deep Neural Networks
The MIT project isn’t the first to consider the idea that computers could automatically associate audio and imagery. But the research being done at MIT may well be the first to pursue it at scale, thanks to the “renaissance” in deep neural networks, which involve multiple layers of neural units that mimic the way the human brain solves problems. The networks require churning through massive amounts of data, and so they’ve only taken off as a meaningful AI technique in recent years as computers’ processing power has increased.
That’s led just about every major technology company to go on hiring sprees in a bid to automate services like search, surfacing relevant photos and news, restaurant recommendations, and so on. Many consider AI to be perhaps the next major computing paradigm.
“It is the most important computing development in the last 20 years,” Jen-Hsun Huang, the CEO of Nvidia, one of the world’s largest makers of the kinds of graphics processors powering many AI initiatives, told Fast Company last year, “and [big tech companies] are going to have to race to make sure that AI is a core competency.”
Now that computers are powerful enough to begin utilizing deep neural networks in speech recognition, the key is to develop better algorithms, and in the case of the MIT project, Harwath and Glass believe that by employing more organic speech recognition algorithms, they can move faster down the path to truly artificial intelligent systems along the line of what characters like C-3PO have portrayed in Star Wars movies.

To be sure, we’re many years away from such systems, but the MIT project is aiming to excise one of the most time-consuming and expensive pieces of the translation puzzle: requiring people to train models by manually labeling countless collections of images or vocabularies. That laborious process involves people going through large collections of imagery and annotating them, one by one, with descriptive keywords.
Harwath acknowledges that his team spent quite a lot of time starting in late 2014 doing that kind of manual, or supervised, learning on sound files and imagery, and that afforded them a “big collection of audio.”
Now, they’re on to the second version of the project, which is to build algorithms that can both learn language as well as the real-world concepts the language is grounded in, and to do so utilizing very unstructured data.
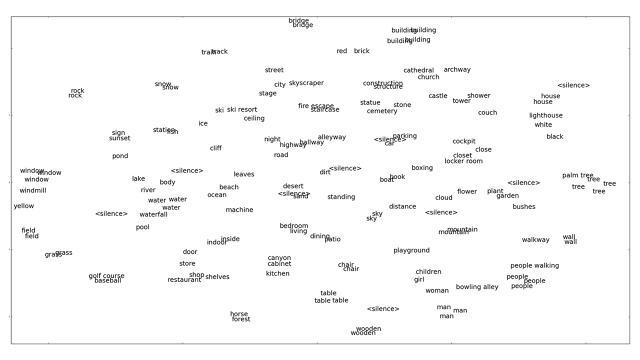
Here’s how it works: The MIT team sets out to train neural networks on what amounts to a game of “which one of these things is not like the other,” Harwath explains.
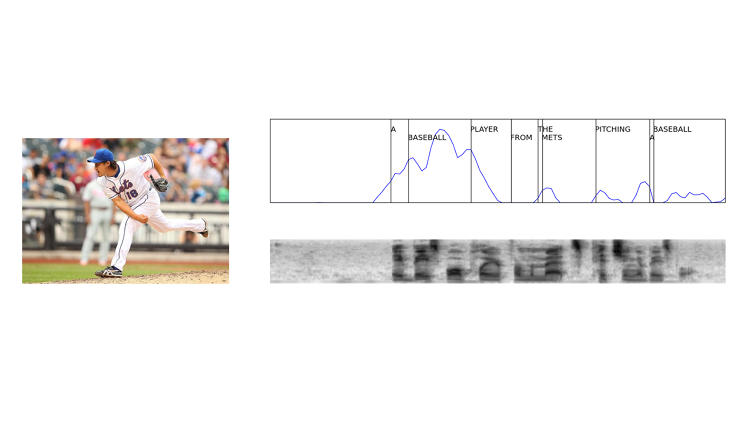
They want to teach the system to understand the difference between matching pairs—an image of a dog with a fluffy hat and an audio clip with the caption “dog with a fluffy hat”—and mismatched pairs like the same audio clip and a photo of a cat.
Matches get a high score and mismatches get a low score, and when the goal is for the system to learn individual objects within an image and individual words in an audio stream, they apply the neural network to small regions of an image, or small intervals of the audio.
Right now the system is trained on only about 500 words. Yet it’s often able to recognize those words in new audio clips it has never encountered. The system is nowhere near perfect, for some word categories, Harwath says, the accuracy is in the 15%-20% range. But in others, it’s as high as 90%.
“The really exciting thing,” he says, “is it’s able to make the association between the acoustic patterns and the visual patterns. So when I say ‘lighthouse,’ I’m referring to a particular [area] in an image that has a lighthouse, [and it can] associate it with the start and stop time in the audio where you says, ‘lighthouse.’”
A different task that they frequently run the system through is essentially an image retrieval task, something like a Google image search. They give it a spoken query, say, “Show me an image of a girl wearing a blue dress in front of a lighthouse,” and then wait for the neural network to search for an image that’s relevant to the query.
Here’s where it’s important not to get too excited about the technology being ready for prime time. Harwath says the team considers the results of the query accurate if the appropriate image comes up in the top 10 results from a library of only about 1,000 images. The system is currently able to do that just under 50% of the time.
The number is improving, though. When Harwath and Glass wrote a paper on the project, it was 43%. Still, he believes that although there are regular improvements and increased accuracy every time they train a new model, they’re held back by the available computational power. Even with a set of eight powerful GPUs, it can still take two weeks to train a single model.

Language To Language
Perhaps the most exciting potential of the research is in breakthroughs for language-to-language translation.
“The way to think about it is this,” Harwath says. “If you have an image of a lighthouse, and if we speak different languages but describe the same image, and if the system can figure out the word I’m using and the word you’re using, then implicitly, it has a model for translating my word to your word . . . It would bypass the need for manual translations and a need for someone who’s bilingual. It would be amazing if we could just completely bypass that.”
To be sure, that is entirely theoretical today. But the MIT team is confident that at some point in the future, the system could reach that goal. It could be 10 years, or it could be 20. “I really have no idea,” he says. “We’re always wrong when we make predictions.”
In the meantime, another challenge is coming up with enough quality data to satisfy the system. Deep neural networks are very hungry models.
Traditional machine learning models were limited by diminishing returns on additional data. “If you think of a machine learning algorithm as an engine, data is like the gasoline,” he says. “Then, traditionally, the more gas you pour into the engine, the faster it runs, but it only works up to a point, and then levels off.
“With deep neural networks, you have a much higher capacity. The more data you give it, the faster and faster it goes. It just goes beyond what older algorithms were capable of.”
But he thinks no one’s sure of the outer limits of deep neural networks’ capacities. The big question, he says, is how far will a deep neural network scale? Will they saturate at some point and stop learning, or will it just keep going?
“We haven’t reached this point yet,” Harwath says, “because people have been consistently showing that the more data you give them, the better they work. We don’t know how far we can push it.”
flower

wooden

archway

baseball
castle

grass

lighthouse

the AI network
plant

room

sky

sunset

train

Fast Company , Read Full Story
(23)