Google DeepMind AI Teaches An Ant To Play Soccer
Deep Reinforcement Learning
David Silver, Google DeepMind, 17th June, 2016
Humans excel at solving a wide variety of challenging problems, from low-level motor control through to high-level cognitive tasks. Our goal at DeepMind is to create artificial agents that can achieve a similar level of performance and generality. Like a human, our agents learn for themselves to achieve successful strategies that lead to the greatest long-term rewards. This paradigm of learning by trial-and-error, solely from rewards or punishments, is known as reinforcement learning (RL). Also like a human, our agents construct and learn their own knowledge directly from raw inputs, such as vision, without any hand-engineered features or domain heuristics. This is achieved by deep learning of neural networks. At DeepMind we have pioneered the combination of these approaches – deep reinforcement learning – to create the first artificial agents to achieve human-level performance across many challenging domains.
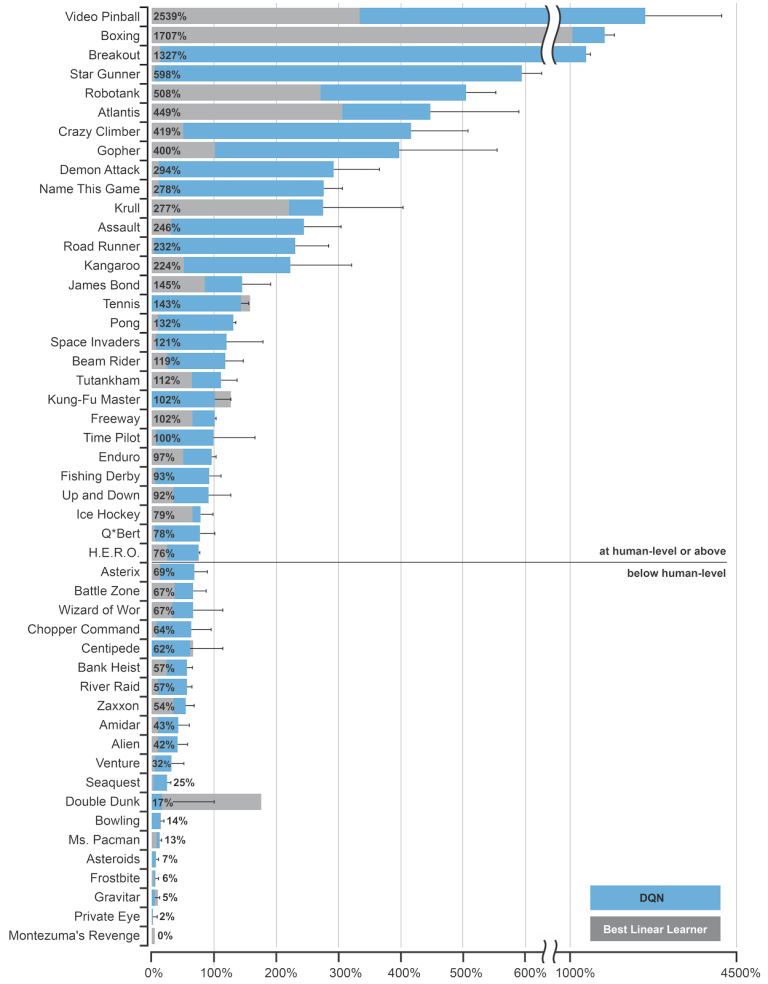
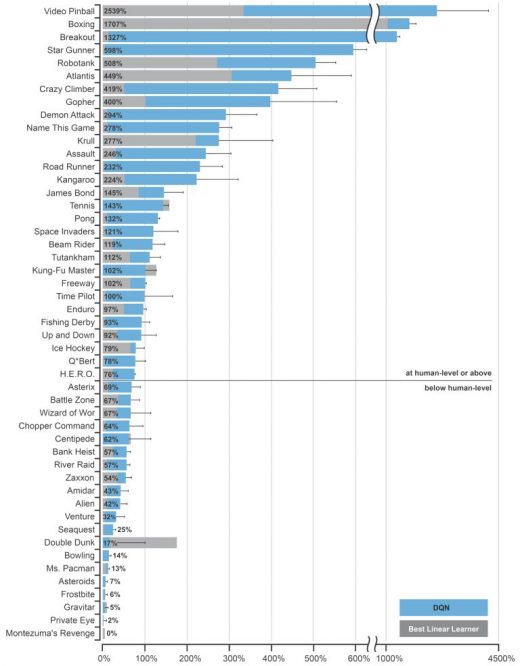
Our agents must continually make value judgements so as to select good actions over bad. This knowledge is represented by a Q-network that estimates the total reward that an agent can expect to receive after taking a particular action. Two years ago we introduced the first widely successful algorithm for deep reinforcement learning. The key idea was to use deep neural networks to represent the Q-network, and to train this Q-network to predict total reward. Previous attempts to combine RL with neural networks had largely failed due to unstable learning. To address these instabilities, our Deep Q-Networks (DQN) algorithm stores all of the agent’s experiences and then randomly samples and replays these experiences to provide diverse and decorrelated training data. We applied DQN to learn to play games on the Atari 2600 console. At each time-step the agent observes the raw pixels on the screen, a reward signal corresponding to the game score, and selects a joystick direction. In our Nature paper we trained separate DQN agents for 50 different Atari games, without any prior knowledge of the game rules.
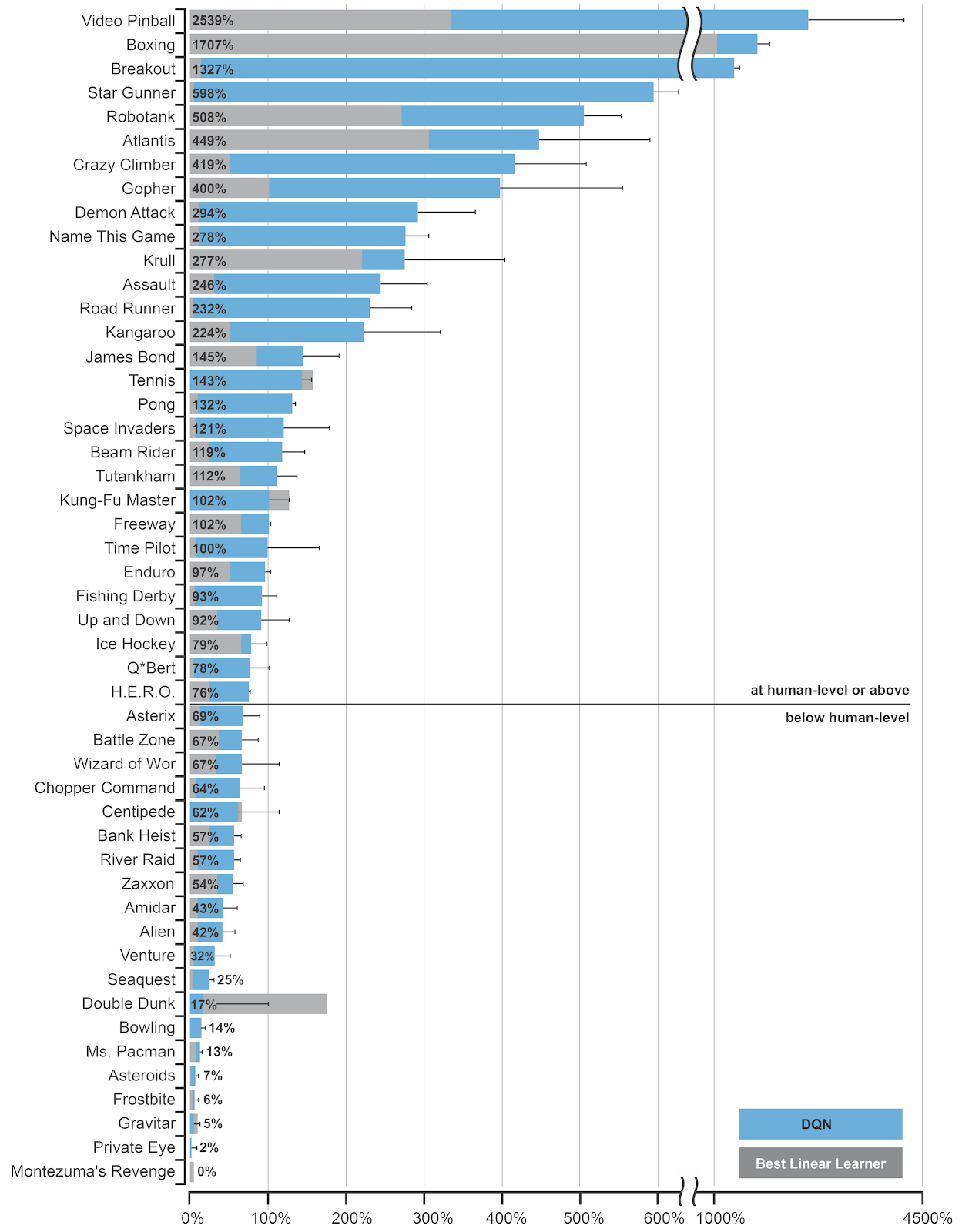
Amazingly, DQN achieved human-level performance in almost half of the 50 games to which it was applied; far beyond any previous method. The DQN source code and Atari 2600 emulator are freely available to anyone who wishes to experiment for themselves.
We have subsequently improved the DQN algorithm in many ways: further stabilising the learning dynamics; prioritising the replayed experiences; normalising, aggregating and re-scaling the outputs. Combining several of these improvements together led to a 300% improvement in mean score across Atari games; human-level performance has now been achieved in almost all of the Atari games. We can even train a single neural network to learn about multiple Atari games. We have also built a massively distributed deep RL system, known as Gorila, that utilises the Google Cloud platform to speed up training time by an order of magnitude; this system has been applied to recommender systems within Google.
However, deep Q-networks are only one way to solve the deep RL problem. We recently introduced an even more practical and effective method based on asynchronous RL. This approach exploits the multithreading capabilities of standard CPUs. The idea is to execute many instances of our agent in parallel, but using a shared model. This provides a viable alternative to experience replay, since parallelisation also diversifies and decorrelates the data. Our asynchronous actor-critic algorithm, A3C, combines a deep Q-network with a deep policy network for selecting actions. It achieves state-of-the-art results, using a fraction of the training time of DQN and a fraction of the resource consumption of Gorila. By building novel approaches to intrinsic motivation and temporally abstract planning, we have also achieved breakthrough results in the most notoriously challenging Atari games, such as Montezuma’s Revenge.
While Atari games demonstrate a wide degree of diversity, they are limited to 2D sprite-based video games. We have recently introduced Labyrinth: a challenging suite of 3D navigation and puzzle-solving environments. Again, the agent only observes pixel-based inputs from its immediate field-of-view, and must figure out the map to discover and exploit rewards.

Amazingly, the A3C algorithm achieves human-level performance, out-of-the-box, on many Labyrinth tasks. An alternative approach based on episodic memory has also proven successful. Labyrinth will also be released open source in the coming months.
We have also developed a number of deep RL methods for continuous control problems such as robotic manipulation and locomotion. Our Deterministic Policy Gradients algorithm (DPG) provides a continuous analogue to DQN, exploiting the differentiability of the Q-network to solve a wide variety of continuous control tasks. Asynchronous RL also performs well in these domains and, when augmented with a hierarchical control strategy, can solve challenging problems such as ant soccer and a 54-dimensional humanoid slalom, without any prior knowledge of the dynamics
The game of Go is the most challenging of classic games. Despite decades of effort, prior methods had only achieved amateur level performance. We developed a deep RL algorithm that learns both a value network (which predicts the winner) and a policy network (which selects actions) through games of self-play. Our program AlphaGo combined these deep neural networks with a state-of-the-art tree search. In October 2015, AlphaGo became the first program to defeat a professional human player. In March 2016, AlphaGo defeated Lee Sedol (the strongest player of the last decade with an incredible 18 world titles) by 4 games to 1, in a match that was watched by an estimated 200 million viewers.

Separately, we have also developed game theoretic approaches to deep RL, culminating in a super-human poker player for heads-up limit Texas Hold’em.
From Atari to Labyrinth, from locomotion through manipulation, to poker and even the game of Go, our deep reinforcement learning agents have demonstrated remarkable progress on a wide variety of challenging tasks. Our goal is to continue to improve the capabilities of our agents, and to use them to make a positive impact on society, in important applications such as healthcare.
(78)