
Google Shares Update On Building Its Speech Models For AI
Google Provides Update On AI Speech Models

Google’s Universal Speech Model (USM) is a critical first step toward creating artificial intelligence (AI) that can understand and translate 1,000 languages.
The company earlier this week shared details of its AI universal speech model designed to understand hundreds of spoken languages. The model is trained on 12 million hours of speech and 28 billion sentences of text spanning more than 300 languages.
The group had to face two significant challenges in automatic speech recognition (ASR). First, a lack of scalability with conventional supervised learning approaches. A fundamental challenge of scaling speech technologies to many languages is obtaining enough data to train high-quality models.
Second, models must improve in a computationally efficient manner while expanding the language coverage and quality, which requires the learning algorithm to be flexible, efficient, and generalizable. The algorithm should be able to use large amounts of data from a variety of sources, enable model updates without requiring complete retraining, and generalize to new languages and use cases.
Google said early tests of the model were designed to create captions on YouTube videos and can perform automatic speech recognition on 100 languages. Some of the languages are spoken by fewer than twenty million people, making it very difficult to find the training data.
A Google Research paper written by dozens of contributors highlights two types of models produced through pre-trained models that can be fine-tuned on downstream tasks, and generic automatic speech recognition (ASR) models for which the researchers assume no downstream fine-tuning occurs. The generic ASR models, Google researchers claim, are scalable method for extending the performance of these models trained on shorter utterances to very long speech inputs.
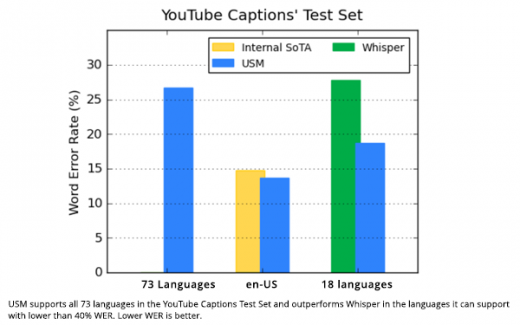
It’s about scaling speech recognition beyond 1,000 languages. The group also built an ASR model for YouTube captioning, the transcription of speech in YouTube videos, that achieves a 30%-word error rate on 73 languages. With only 90,000 hours of supervised data, this model performs better than Whisper, a general ASR system trained on more than 400,000 hours of transcribed data.
The paper can be found here.
(19)
