
New Data On Open Source: Reinventing The Wheel Every Day
New data on open source: Reinventing the wheel every day

New data from the open source reveals the story of a simple javascript function re-invented over 100 times and duplicated over 1,000 times across GitHub’s top 10k repositories. This is only a symptom of a much deeper problem.
Imagine every time you wanted to drive a car, you had to build new wheels. People would probably still be riding horses to work. Elegant, some might say, but a terrible waste of time and effort. New data shows this is exactly what is happening in 2017 when developers are trying to use even the smallest of functionalities across repositories and microservices.
Code components are the fundamental building blocks of any application. In some ways, they are the atomic building blocks of our technological future. Different functionalities can and should be reused across different applications, repositories and projects. In practice, this rarely happens. Instead, people often re-invent or duplicate the same code over and over again. This happens because of the lack of a better alternative. The overhead of creating, configuring and maintaining an arsenal of tiny repositories and micro-packages for hundreds of reusable components isn’t practical.
To see how deep and how far the phenomenon of reinvesting or duplicating small components really goes, we took a deep look into the guts of the open source on GitHub.
The Story Of `isString`
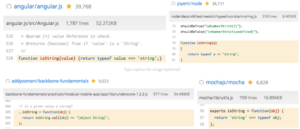
To better understand the scale of this phenomenon, a semantic code identification technology was used to take a deep look into the guts of the open source on GitHub. The top 10,000 Javascript repositories were scanned analyzed looking to see how many times people reinvented or duplicated one simple functionality: checking if a variable is a string. Normally, this can be done with 1-3 lines of code. Here are the results:

This simple functionality had been written in more than 100 different ways across only 10K repositories. The top 10 implementations were duplicated over 1,000 times. Given that GitHub holds over 55 Million repositories, simple math shows that the same function was probably re-invented tens of thousands of times and duplicated millions of times across the open source. Here are a few examples of how some top community projects reinvented the same 1-4 lines of code:

Although it is true that change is necessary for evolution, these numbers mean bad new for everyone, for two main reasons:
First, constantly reinventing small pieces of code takes time and effort. Not only is it wasteful, but it actually holds back innovation by competing for the same time and resources which could better have been invested in building new things.
Second, code duplications are bad. Trying to fix of update a code component duplicated across dozens of places is hard and takes terrifying amounts of time, and is also likely to break stuff. The larger the code base and the more repositories you have, the worse it becomes.
Why is it happening
The obvious solution would be to make code components reusable across repositories. Much had been said about code reusability. Renown community members post about designing reusable pieces of code. Others debate and struggle to force small components into their own repositories and packages. Most agree, there are three major problems that prevent us from building an arsenal of hundreds of small reusable components:
- Creation Overhead: Creating a new repository and a package for every small component will take a lifetime. There is simply too much duplication and configuration overhead required to make this process practical at scale.
- Maintenance: maintaining dozens or hundreds of tiny repositories and packages is no joke and neither is modifying small packages going through multiple demanding steps every time (cloning, Linking, debugging etc.). This may very well end up taking more time and effort than it could save.
- Discoverability: packages are hard to find. No one can say for sure what’s really out there, or what to trust and use (we all remember the left-pad story). Organizing hundreds of micro-packages and quickly finding the right one to use is no easy taks.
Bottom line is, very few people create and maintains such an arsenal of micro-packages. These are 3 barriers that block the road to true reusability, on the long journey towards composing code out of smaller, isolated components.
Rethinking The Paradigm: Write Code Once, Use It Anywhere
So, how can we change things? A good place to start truly solving this problem would be dealing with the three problems mentioned above: making reusable components simple to create, maintain and find.
To do exactly that, a new open source project called Bit has been recently released to GitHub. Bit is a virtualized code component repository that allows developers to easily build a scalable set of reusable components and use them across different repositories without creating duplications.

In a way that might sound somewhat similar (although different) to what Docker did for VMs, Bit adds a virtualized level of abstraction on top of your source files, addressing code components directly. By doing that, Bit allows you to create reusable components with almost no overhead at all and use them as a virtual API containing nothing but the code actually used in your application.
Bit solves all of the three problems mentioned above using a virtual repository called a “Scope“. A Scope allows you to create and model components without the overhead we know today, and then find them using a unique NLP based semantic search engine and reuse them anywhere. It uses a special configurable environment emit to build and test components anywhere using any framework. Scopes are distributed by nature, which adds similar advantages known from a distributed Git repository. They can be created anywhere, and even connected to create a distributed network. A free community Hub called bit source can also be used to create and manage different Scopes and components for single developers or entire teams, making them reusable in different projects and applications.
Conclusion
Code duplications (or reinvention) are a serious problem, and the data drawn from GitHub shows how widespread it really is. This is happening mainly because there isn’t a practical alternative that makes it possible to create a growing set of reusable components. Open source projects such as Bit or others can help solve this problem, saving valuable time and effort.
Bit is language agnostic by design, and uses special drivers to work with different languages. In the not so distant future, we could all work with virtual code bases composing pieces of code together to build anything (as described in the Unix philosophy). Meanwhile, using Bit or finding new ways to reuse atomic components would be a good place to start.
The post New Data On Open Source: Reinventing The Wheel Every Day appeared first on ReadWrite.
(46)











